Nejste přihlášen/a.
Dobrý den,
hledám nějaký program nebo online converter, co dokáže, jedná se asi o deset tisíc souborů.., v těchto souborech zrušit CZ diakritiku? Nejlépe abych všechny soubory, nebo po menších částech, upravil naráz.Něco jsem našel, ale buď to umí předělat pouze diakritiku samotného souboru,což nepotřebuju,nebo to chce paste textu ze soouboru, pak vložit a pak po nějakém 10 vteřinovém časovači to mohu stáhnout... Díky
3x

Jaké mají soubory kódování a jaké chcete cílové? jsou soubory v jednom adresáři?
Na toto se hodí iconv
find /path/to/folder -type f -exec sh -c iconv -f UTF-8 -t ASCII//TRANSLIT "{}" -o "{}.tmp" && mv "{}.tmp" "{}" \;
případně
find /path/to/folder -type f -exec sh -c iconv -f UTF-8 -t ASCII//TRANSLIT "{}" -o "{}.new" \; # výstup jsou soubory s příponou, což bude lepší
(pozor na konci je zpětné_lomítko ; , to ale zdejší systém vymaže) a uvozovky taky
1x
Asi pirátská hra a někdo rozjeb... kódování...
Zkus vygooglit ten tajnej "název hry" + čeština
asi už ten problém někdo někdy řešil..
A kdyby ne, Vyhledat soubor s textem kt. se zobrazil správně-asi bude UTF8, že?
0x
Není to optimální, ale udělat náhradu pro každý znak s diakritikou. Teda soubory musí být textové a asi i ve vhodné kódové stránce. Pak to jde třeba v dobrém českém editoru PSPad. Tam to pak vypadá takto:

Já našel toto, je to vcelku dobré, ale ne na větší várku souborů. onlinetexttools.com/... Kouknu, co ten PSPad umí. Díky
0x
Vojín Kotas, já mám dotaz:
Ty soubory jsou jen textové (jaké je kódování?) nebo jsou obecné a ten program by měl nejdřív vyhledávat co je text?
Teď už jsem mimo, kdysi jsem napsal prográmek co v souboru DXF hledal kód (%%+třímístné číslo) a nahradil ho jedním osmibitovým číslem (převod výkresu z MS DOS do woken).
No jsou to malé soubory velikosti od 1kB do cca 300kB s příponou int. Dají se ale normálně přes Total Com. editovat přes F3.. a upravovat úplně s poklidem. Ale je jich vela... No prostě se jedná o hru, co špatně zobrazuje diakritiku - klkiháky a kdybych se zbavil diakritiky, tak je to ok. Ale je to jen jedna z mnoha, tak nechci řešit nastavení systému... Zkoušel sem language a vše možné v systému a nepomohlo. Dál se v systému rýpat nechci a diakritiku nepotřebuji..., tedy se jí rád zbavím.![]()
Přidávím se k otázce "Jaké je kódování"? Třeba jen máte to kódování špatně nastaveno.
V jakém editoru / prohlížeči se vám jeví kódování špatné?
Když je souborů moc, pomohl by dávkový cyklus for *.int in (cesta)
+ něco z tohoto
How-to: Edit/Replace text within a Variable
https://ss64.com/nt/syntax-replace.html
Tak to nedokážu zjistit. To kódování. Nejsem programátor a nevím přes jakou utilitu.. Když dám vlastnosti souboru ať přes T.C. nebo i přes průzkumníka, tak nic nevyhledám... Jinak když tu hru spustím, tak znaky co nemají čárky a háčky, jsou ok, ostatní mají něco jak nějaký čínský znak - vše vypadá stejně. Dá se to většinou přečíst i tak, ale někdy je to moc a to luštění zdržuje...Tady přidám náhled, co např. potřebuji změnit. Ale jak říkám, je toho na tisíce a někdy i s mnohem delším textem...
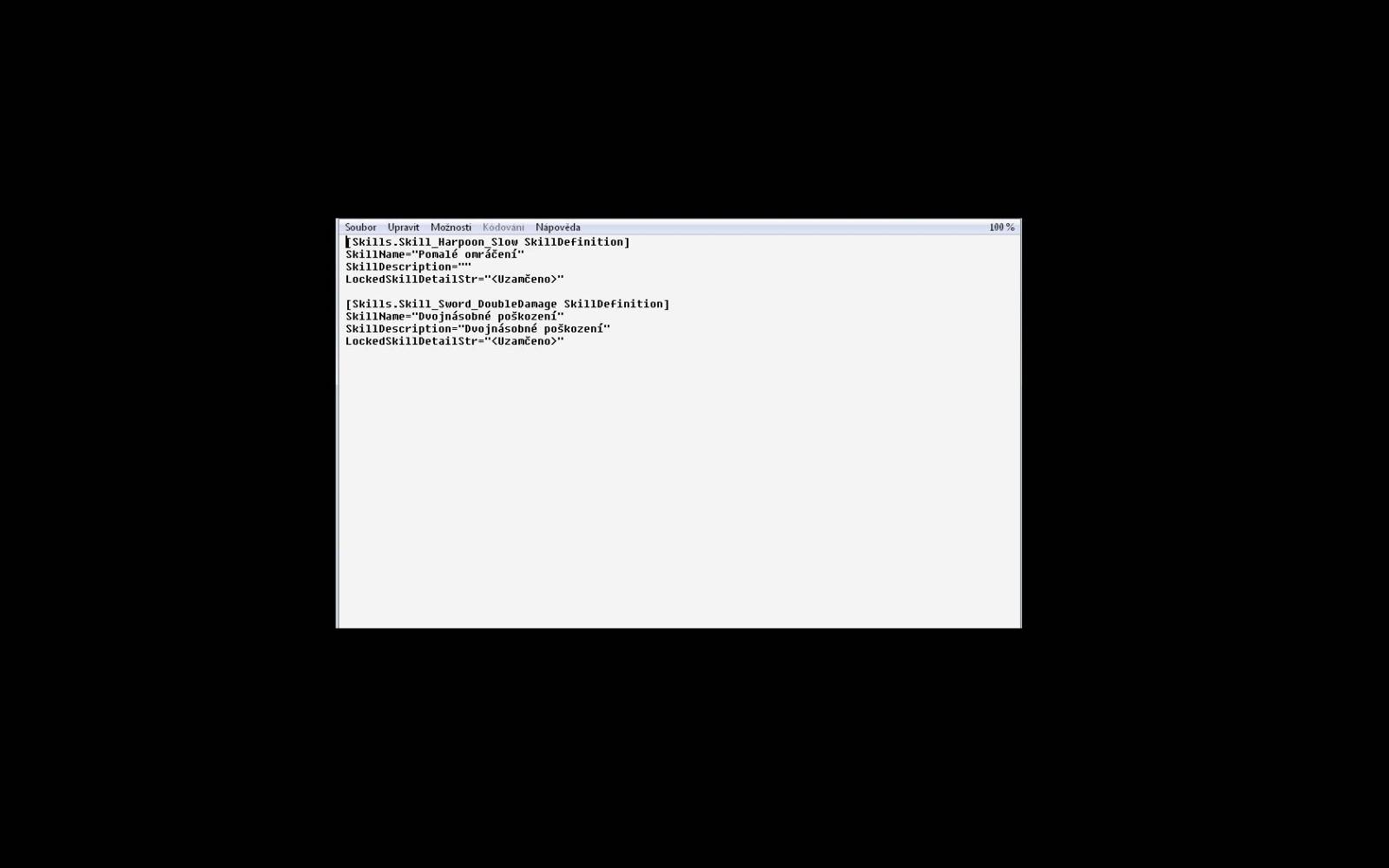
Zkoušel jsem vše možné, ale kódování nezjistil. Tak sem alespoň jeden soubor nahrál sem pro náhled.. webshare.cz/...
Ukázka je v kódování UTF-16 LE BOM.
Stáhněte si Notepad++
V nabídce Encoding / Kódování je možné text překódovat na nějaké obvyklejší kódování, tedy na to, jaké vaše hra podporuje. Nevíme, jaké to je, ale předpokládám že UTF-8 by měla zvládnout.
Na konverzi kódování je možné si udělat v Notepadu makro na jednu klávesovou zkratku.
Také existuje plugin do Notepadu++ s názvem AutoCodepage, který dávkově převede soubory na požadovanou kódovou stránku. UTF-8 je kódová stránka 65001 (utf-8 Unicode UTF-8) .
Já bych si to prostě zkopíroval někam vedle, zkusmo zkonvertoval z UTF8 do ASCII a prošel několik souborů, jestli se tam správně oddiakritikovala všechna písmenka. Pokud ne, tak bych to zkusil s jiným kódováním. Přinejhorším se to povede na třetí pokus.
(teda, já bych si vzal všechna písmenka ze všech souborů, setřídil podle abecedy a měl bych všechny použité znaky na jedné hromadě a podle nich si vybral dekódování, ale pro mě není problém napsat krátký skript a nechat ho to zpracovat.)
Jo, cestou pokus - omyl je nutné zjistit tu správnou kódovou stránku / kódování.
To snad tazatel zvládne.
P.S.
Originál není UTF-8.
Ok, díky. Ale už jsem si poradil přes ten jeden odkaz co jsem tu dával a ono si to postupně během hry říká o další soubory.. Některé se mi navíc ukazují správně s diakritikou. Tak jsem koukal, že jich je asi "jen" 300... včetně DLC, což ale hrát stejně asi nebudu. Takže to vypadá na nějakých 100 souborů a to dám kdyžtak ručně. Ale zkusím ten postup přes Notepad++. Kdysi jsem ho taky měl.
Unicode, alias Universal Coded Character Set, zahrnuje
UTF-8, UTF-16, UTF-32
---
a to ještě nepočítám varianty LE / BE (Little Endian / Big Endian) a BOM / without BOM (BOM = byte-order mark)
Vyřešeno přes Audrey Diacritics Remover. Sice se to musi klikat soubor po souboru ale jde to rychle.Kódování v tom programu musím zadávat UNICODE, jinak to konvertuje špatně. Všem díky.
" ... zadávat Unicode " ... jaké Unicode? Není Unicode jako Unicode ...
To už byste měl jednodušší s Notepadem ++.
Ale že už je to vyřešeno.
Příjemné vánoce.
Neneseme odpovědnost za správnost informací a za škodu vzniklou jejich využitím. Jednotlivé odpovědi vyjadřují názory jejich autorů a nemusí se shodovat s názorem provozovatele poradny Poradte.cz.
Používáním poradny vyjadřujete souhlas s personifikovanou reklamou, která pomáhá financovat tento server, děkujeme.