Nejste přihlášen/a.

Dobrý den, potřebovala bych převádět obrázky na text nějaký programem, který by se pouštěl v terminálu (linux mint).
Zkoušela jsem v python3:
from PIL import Image
from pytesseract import image_to_string
img = Image.open(2.jpg)
text = image_to_string(img)
print (text)
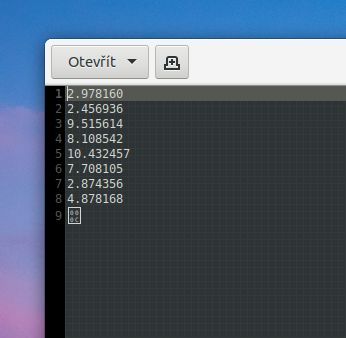
výstup byl:
2.832034
2.408290
24.984529
9.561579
14.477622
4.014763
" 8.221435,
" 3.548312
3.514344
4211277
2.482226
1.160587
tj. chytí jedna desetinná tečka, místo minusu jsou uvozovky.
Zkoušela jsem obrázek zvětšovat, nastavit kódování, nepomohlo.
from PIL import Image
from pytesseract import image_to_string
import cv2
img = cv2.imread(2.png, cv2.IMREAD_UNCHANGED)
print(type(img))
print(Original Dimensions : ,img.shape)
scale_percent = 400 # percent of original size
width = int(img.shape[1] * scale_percent / 100)
height = int(img.shape[0] * scale_percent / 100)
dim = (width, height)
# resize image
resized = cv2.resize(img, dim, interpolation = cv2.INTER_AREA)
print(Resized Dimensions : ,resized.shape)
with open(obr.txt, mode=w, encoding=utf-8) as a_file:
a_file.write(image_to_string(image))
Stáhla jsem už hotový program - hlásí to error:
linux@LINUXMINT:~/.local/lib/python3.6/site-packages/text_to_image$ python3 decode.py image.png Traceback (most recent call last): File "decode.py", line 60, in print(decode(args.image_path)) File "decode.py", line 27, in decode decoded_text += chr(pixel_value) TypeError: an integer is required (got type tuple)
linux@LINUXMINT:~/.local/lib/python3.6/site-packages/text_to_image$ python3 decode.py -f my-text-file.txt image.png Traceback (most recent call last): File "decode.py", line 62, in output_file = decode_to_file(args.image_path, args.file) File "decode.py", line 44, in decode_to_file decoded_text = decode(image_path) File "decode.py", line 27, in decode decoded_text += chr(pixel_value) TypeError: an integer is required (got type tuple)
Nemáte prosím někdo nápad, jak upravit ten kód, aby to fungovalo správně, jak opravit ten error u stáhnutého balíčku, odkaz na program nebo kód, který to tohle uměl? Děkuji


A jak to poznám prosím? Je to screenshot z jednoho programu, s lepším rozlišení to asi neudělám. Zkoušela jsem převádět obrázek do greyscale, také to nepomohlo.
tohle není tak docela pravda viz článek zde developex.com/... kde vhodná metoda upscalignu zlepšila detekci o 80%, tedy skutečně naprosto zásadním způsobem. Nestačí ale jednoduchý upscaling, tady je třeba skutečně použít takový co se snaží detekovat podobu křivky ztracenou hrubým rastrem. Takových metod je celá řada, výborná je třeba metoda ESRGAN, která využívá pro upscaling neuronovou síť (AI) a má téměř zázračné výstupy ![]() které účinnost ocr metod umí zvýšit velmi znatelně.
které účinnost ocr metod umí zvýšit velmi znatelně.
0x
mě to jde do textu přeložit výborně s pomocí tesseract.
Nainstaluješ ho příkazem sudo apt install tesseract-ocr
A pak jen spustíš s parametry vstupu, výstupu a metody vyhledávání textu příkazem
tesseract --psm 6 vstup.jpg vystup.txt
S metodou psm 6 to funguje nejlíp protože je to souvislý blok, všechny metody jsou popsány zde github.com/... v kapitole Page segmentation method, je jich celkem 13.
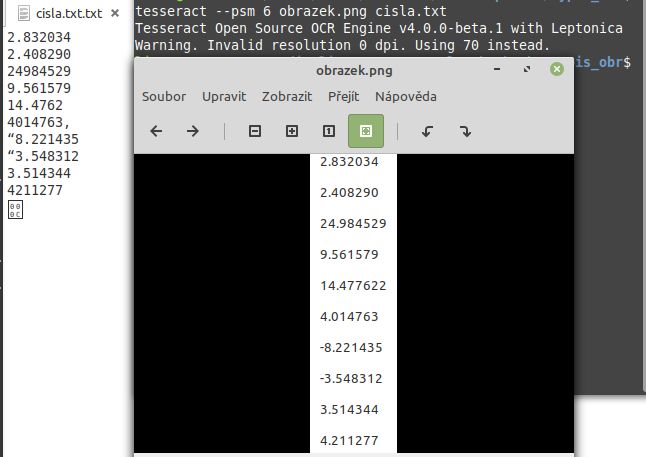
výstup je pak u mě takovýto pěkný txt soubor
horší je to s těmí mínusky no, ty nerozpoznává tak spolehlivě pokud jsou hned prvním znakem v řádku. Pomohlo by ta čísla uvádět třeba do uvozovek, pak by to mínusko rozpoznal spolehlivě např "-10.342457" tedy i s uvozovkami nebo dát na začátek jakýkoliv jiný znak po kterém už mínusko považuje za skutečný symbol a ne jenom vadu tisku.
Neneseme odpovědnost za správnost informací a za škodu vzniklou jejich využitím. Jednotlivé odpovědi vyjadřují názory jejich autorů a nemusí se shodovat s názorem provozovatele poradny Poradte.cz.
Používáním poradny vyjadřujete souhlas s personifikovanou reklamou, která pomáhá financovat tento server, děkujeme.