Nejste přihlášen/a.

Dobrý den, umíte někdo prosím v proframovacím jazyku awk?
doplněno 21.12.18 13:34:
Mám soubor a potřebuji vypsat čísla z tabulky Input-Output in F Format z 5. a šestého sloupce - řádek 27947.
Mám příkaz:
awk /^$/{flag=""} /Input-Output in F Format/{flag=1;next} flag && ($0 ~ /^[0-9]/ ||
$0 ~ /^ [0-9]+/) && ($0 !~ /26 0/ && $0 !~ /28 0/){print t($5),t($6)} function t(n, s) { s=index(n,"."); return (s? substr(n,1,s+6) : n) } dcout1.active > a
A potřebovala bych tam napsat, že to má vybírat jen z té jedné tabulky - z oblasti od /Input-Output in F Format/ do /Input-Output in D Format/. V tom příkazu je něco s prázdou řádkou, nechápu ten zápis s flag, co jsem hledala na internetu, bylo to mnohem srizumitelnější. To co je v tom příkazu, tak funguje na soubor, kde jsou zkopírované jen ty dvě tabulky, ale ne na celý soubor, to se vypisují i hodnoty z druhé tabulky.
Pak bych to chtěla vypisovat jedno číslo na jednu řádku, ne dvě čísla na jednu řádku.
Dále bych chtěla vědět, jak zapsat, aby se místo toho čísla v 5./6. sloupci v té tabulky vypsano nějak upravené - vynásobené 1000, nebo vydělené pi.
($0 ~ /^[0-9]/ || $0 ~ /^ [0-9]+/) - tohle je, že řádek začíná číslicí nebo mezerou a pak číslicí, ale nechápu ty jednotlivé znaky.
Moc děkuji
doplněno 21.12.18 14:26:
Když by bylo více vstpuních souborů, jde ty výsledky - z jednoho souboru jeden sloupec, zapisovat jako sloupce vedle sebe?
2x
Do souboru nazev.awk napiš:
{nalez=0;
while (nalez == 0) {
if ($0 ~/Input-Output in F Format/) {nalez=1; printf ("OK %d", NR); continue}
next;}
getline;getline;getline;
printf ("
while %d
",NF);
while (NF == 6) {
if ($1 ~/[0-9]/) {printf ("%d - %s
", $5*1000, $6/3.14);getline}
}
}
Volá se awk -f nazev.awk dcout1.active
Je tam několik printf jen pro kontrolu co se děje a printf lze nahradit třeba sprintf atp... to záleží na awk pro konkrétní platformu a jak budeš potřebovat formát výst. dat.
%s a %d jsem schválně dal různé i když se jedná o čísla, vyhovující formát výstupních dat který ti bude vyhovovat si budeš muset najít sám.
Lze i do více sloupců, ale v awk by to asi bylo nejjednodušší dělat přes pole[počet souborů][10].

Ten můj příkaz dává:
awk -f out_par dcout1.active
43.678664
0.106651
0.080232
0.000675
2.728532
0.011542
-0.000275
0.001980
0.219549
0.001770
83.921141
0.115844
3.939209
0.005293
7.494242
0.009195
0.436786
0.106651
0.802325
0.675580
0.272853
0.115424
-0.275491
0.198014
0.219549
0.177072
0.839211
0.115844
0.224994
0.479612
0.393920
0.529363
0.749424
0.919555
A potřebovala bych odstranit to červené, to je z té druhé tabulky.
Děkuji a šlo by ještě prosím, aby to bylo s desetinnými tečkami nebo čárkami a každé číslo na jednom řádku?
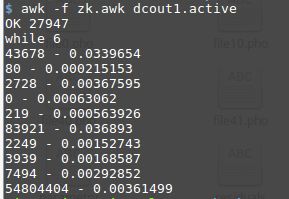
Neznám tvůj konkrétní awk, formátování printu i kompletní help gnu.org/...
Na jeden řádek místo mezera mínus mezera dáš zpětné lomítko a n.
2x
Ten flag funguje jako přepínač.
Když se program začne, je flag rovno 0. A když je 0, tak se neprovádí ta čast flag &&... Ale když se narazí na ten řetězec, u kterýho se má začít, tak se flag přepne na jedna a v dalším kroku se ta část už provádí.
Připadá mi, že se vám srazily řádky, bez nich to nejde rozluštit, ty řádky jsou v AWK důležité.
Neneseme odpovědnost za správnost informací a za škodu vzniklou jejich využitím. Jednotlivé odpovědi vyjadřují názory jejich autorů a nemusí se shodovat s názorem provozovatele poradny Poradte.cz.
Používáním poradny vyjadřujete souhlas s personifikovanou reklamou, která pomáhá financovat tento server, děkujeme.