Nejste přihlášen/a.

V Excelu potřebuju texty s několika slovy v buňkách sloupce rozdělit do sloupců dvou, aby v každé buňce bylo samostatné slovo.
Vím, že to jde, ale dávno jsem zapomněl jak ![]() .
.
doplněno 19.12.18 22:01:
No já vím, že jsem to napsal trochu zmateně ![]() . Podle obrázku to snad bude srozumitelnější.
. Podle obrázku to snad bude srozumitelnější.
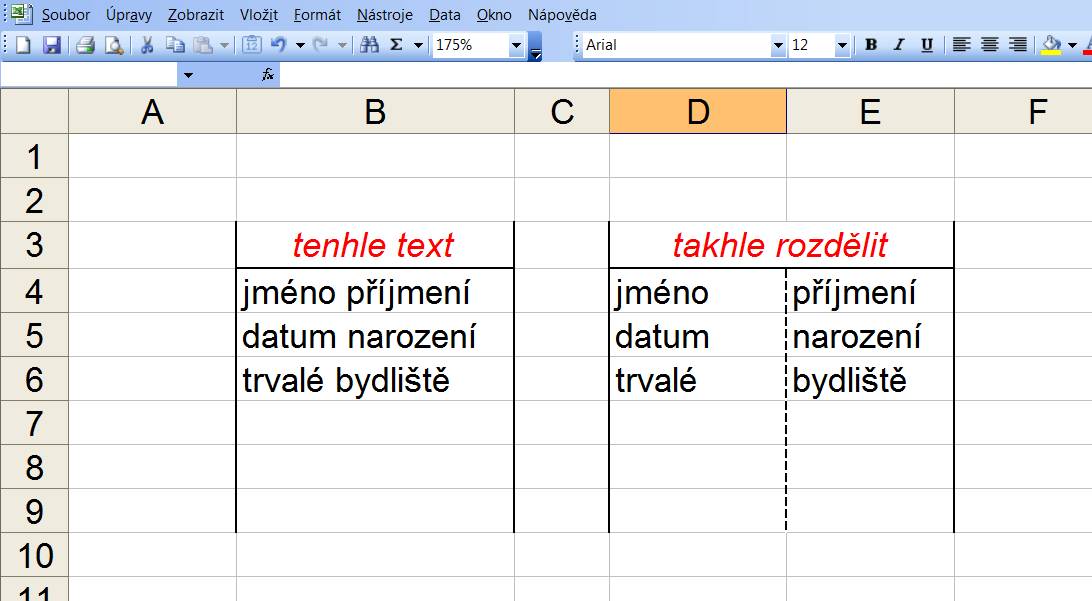
2x
wall.cz/...
doplněno 20.12.18 19:45:
Tak v tom to případě jedině nahradit požadované mezery jedinečným znakem, podle kterého by se poté provádělo rozdělení textu. Dala by se k tomu využít fce DOSADIT a její poslední parametr "instance", který určuje kolikátý výskyt v pořadí se má nahradit. viz soubor
Otázkou je kolik takovýchto dat je a jak často se bude měnit pozice jedinečného znaku. Aby nakonec nebylo rychlejší provést rozdělění textu ručně.
Tak ještě to není ono ![]() . Problém je ten, že v původním textu je těch mezer víc a ne v každé to potřebuju rozdělit. Dá se nějak určit, podle které se to má dělit? Třeba i ve více krocích.
. Problém je ten, že v původním textu je těch mezer víc a ne v každé to potřebuju rozdělit. Dá se nějak určit, podle které se to má dělit? Třeba i ve více krocích.
2DS servis (Kanalizace) 602333223 774446550 Čištění kanalizace
rozdělit na
2DS servis (Kanalizace) 602333223 774446550 Čištění kanalizace
lobo - Hmmm... Tak vzhledem k tomu, že ten text v každé buňce vypadá jinak a že to potřbuju dělat jen párkrát do roka, bude to asi fakt jednodušší rozdělit ručně ![]() . 250 řádků se dá se zaťatými zuby zvládnout.
. 250 řádků se dá se zaťatými zuby zvládnout.
Buď tak, nebo si v těch datech najít nějaký systém.
Největší bordel bude dělat "firma". Pokud by si ji z řetězce odstranil (ručně nebo vzorcem) zbytek už by šel celkem snadno, pokud tedy budu brát, že na druhé a třetí pozici jsou telefonní čísla (neměnný počet znaků - opět za předpokladu, že jsou včechna zadána stejně, tedy bez mezinárodní předvolby[+420]).
Pokud je to vždycky po třetí mezeře, tak je to variace původního zadání. Pokud je těch mezer na počátku různě, tak by to šlo třebas od konce.
Pokud by rozdělení textu začínalo vždy po třetí mezeře, tak to bude brnkačka. Ale tak to nejspíš nebude. S tím zpracováním od konce máš pravdu to by byla možnost, ale obávám se (vzhledem k tomu jaký vzorek dat autor poskutnul), že to bude stejné jako s tím začátkem.
Právě to byl důvod, proč sem chtěl přiložit vzorový soubor. Zadání nikdy neodpovídá realitě.
0x

Pozici první mezery
do buňky ve sloupci D vložit znaky od začátku do té mezery (o jeden méně)
do buňky ve sloupci E vložit znaky od pozice mezery do konce
To je algoritmus; jména příslušných funkcí si snad najdeš.
Vzhledem k tomu, že v každém textu byl jiný počet mezer (navíc občas někde chyběly), jiný počet znaků, jiný počet slov a dokonce jiný počet telefonních čísel, zvolil jsem "poloautomatickou" metodu v několika krocích. Oddělil jsem text ve 2 mezeře, tím jsem získal 1 sloupec se jmény a čísly bytů (jména firem). Drobné nesrovnalosti jsem opravil ručně, moc jich nebylo. Zbytek jsou devítimístná telefonní čísla (v každém řádku je jich ale rozdílný počet), takže jsem oddělil 9 znaků zleva, v dalším kroku z toho, co zbylo dalších 9 znaků zleva a tím zbylo posledních 9 znaků. Není to ideální způsob, ale pro prakticky jednorázové použití je to přijatelné.
Dík všem za rady.
doplněno 21.12.18 13:19:
Pro ilustraci ještě přikládám obrázek, jak ten seznam původně vypadal. Takhle se mi to stáhlo z adresáře mobilu. Jo a aby to snad nebylo moc jednoduché, je před každým tím textem ještě 10 mezer.
Na tohle asi fakt žádný univerzální vzorec neexistuje.

Neneseme odpovědnost za správnost informací a za škodu vzniklou jejich využitím. Jednotlivé odpovědi vyjadřují názory jejich autorů a nemusí se shodovat s názorem provozovatele poradny Poradte.cz.
Používáním poradny vyjadřujete souhlas s personifikovanou reklamou, která pomáhá financovat tento server, děkujeme.