Nejste přihlášen/a.

Mám dva txt soubory ktere z casti obsahuji na radcich stejna data z DB (asi 6000 radku v jednom a 7000 radku v druhem).
Da se to poznat ze stringu na kazdem radku, ktery je v souboru 1 i 2 identicky - jine casti radku jsou bohuzel nestejne (pred/za tim stringem jsou jinaci ![]() Radky jsou navic zprehazene tzn. ze shodny udaj je v jednom souboru na 22. radku a v druhem na radku 1584.
Radky jsou navic zprehazene tzn. ze shodny udaj je v jednom souboru na 22. radku a v druhem na radku 1584.
Potreboval bych do 3. souboru vyseparovat komplet ten 1000 radkovy rozdil.
V jakem nastroji by to slo a jak?
Dekuji za nasmerovani

0x

Excel...
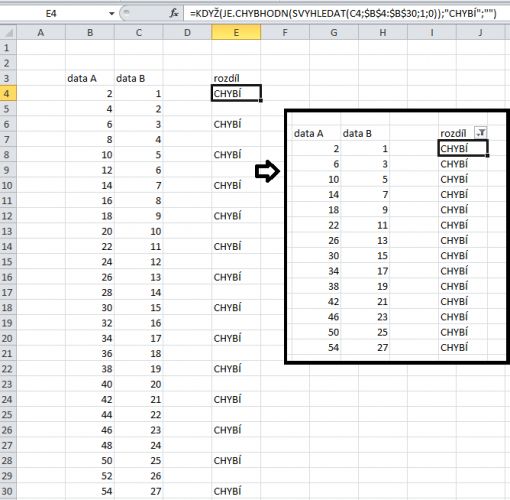
Naimportoval bych si textaky do excelu, funkcí je porovnal a na výsledek hodil filtr a tím zobrazil jen rozdíly viz obr
ve sloupci B jsou sudá čísla, v sloupci C celá řada ...
příkazem =KDYŽ(JE.CHYBHODN(SVYHLEDAT(C4;$B$4:$B$30;1;0));"CHYBÍ";"")
excelu říkám, aby každou buňku v sloupci C porovnal se sloupcem B a pokud tam není, tak aby do buňky napsal text "chybí" ... pak zapnul filtr a vyfiltroval jen slovo "chybí" ... a hotovo
0x
Tohle zvládne i PSPad. Ale export rozdílů do nového texťáku si musíte udělat sám (CTRL+A+C+V).
doplněno 19.06.18 18:57:
Akorát s tím porovnáním na různých řádcích bude problém. PSPad umí poznat prázdné řádky, nebo jednotlivé znaky odřádkované na další řádek a přeskočit je. Ale přes mnoho řádků (ve vašem příkladu přes tisíc) shodu nepozná. Ani si nejsem jistý, jestli existuje SW, který by zvládnul přesně to co chcete. Potřebujete script na míru.
Dekuji za vase vstupy, ale vidim tam problem v tom co pisu:
jine casti radku jsou bohuzel nestejne (pred/za tim stringem jsou jinaci ![]() Radky jsou navic zprehazene tzn. ze shodny udaj je v jednom souboru na 22. radku a v druhem na radku 1584.
Radky jsou navic zprehazene tzn. ze shodny udaj je v jednom souboru na 22. radku a v druhem na radku 1584.
Protoze se domnivam, ze Excel i PSPad to umi pouze na jednom a tom stejnem radku ![]()
Jsem z to to vyseparovat string, jehoz soucasti je hodnota do jedhoho sloupce K, kde je potom uvedeno v prvnim souboru na radku 22
Pardon, nedoslo mi, ze se to predela, tak niz bez toho...
Však v čem je problém? Tak pomocí oddělovače odděl stringy a porovnávej jen je. A co se rozházených řádků týče : já taky ty čísla přeci nemám na stejném řádku. V jednom sloupci mám hodnotu 10 na 8 řádku, v druhém sloupci mám hodnotu 10 až na 13 řádku, ale protože porovnávám úplně každý řádek s každým řádkem, tak ve výsledku číslo 10 chybí, protože jsem si zobrazil jen ty řádky, které se nikde nevyskytují dvakrát. Pokud nechceš jen nasměrovat, ale přímo to udělat, tak dej data...
2 yakub - ja bohuzel nejsem tak zdatny, abych to zvladl bez napovedy - nevim jak rozdelit ten string na zvlastni radek + jaky pouzit vzorec na projiti a zjisteni tech hodnot
radek 22
adresa.cz/i2/i2.search.cls?ictx=PREV&skin=1&language=2&src=PREV_us_auth&ascii=0&fld1=T001&kvant1==&term1=^0040353^&op=nq-2&qt=13&zf=AUF_PREV">Zázn
a na druhem na radku 1584:
adresa.cz/i2/i2.search.cls?ictx=PREV&skin=1&language=2&src=PREV_us_auth&ascii=0&fld1=T001&kvant1==&term1=^0040353^&op=nq-2&qt=13&zf=AUF_PREV">Záznam v DB
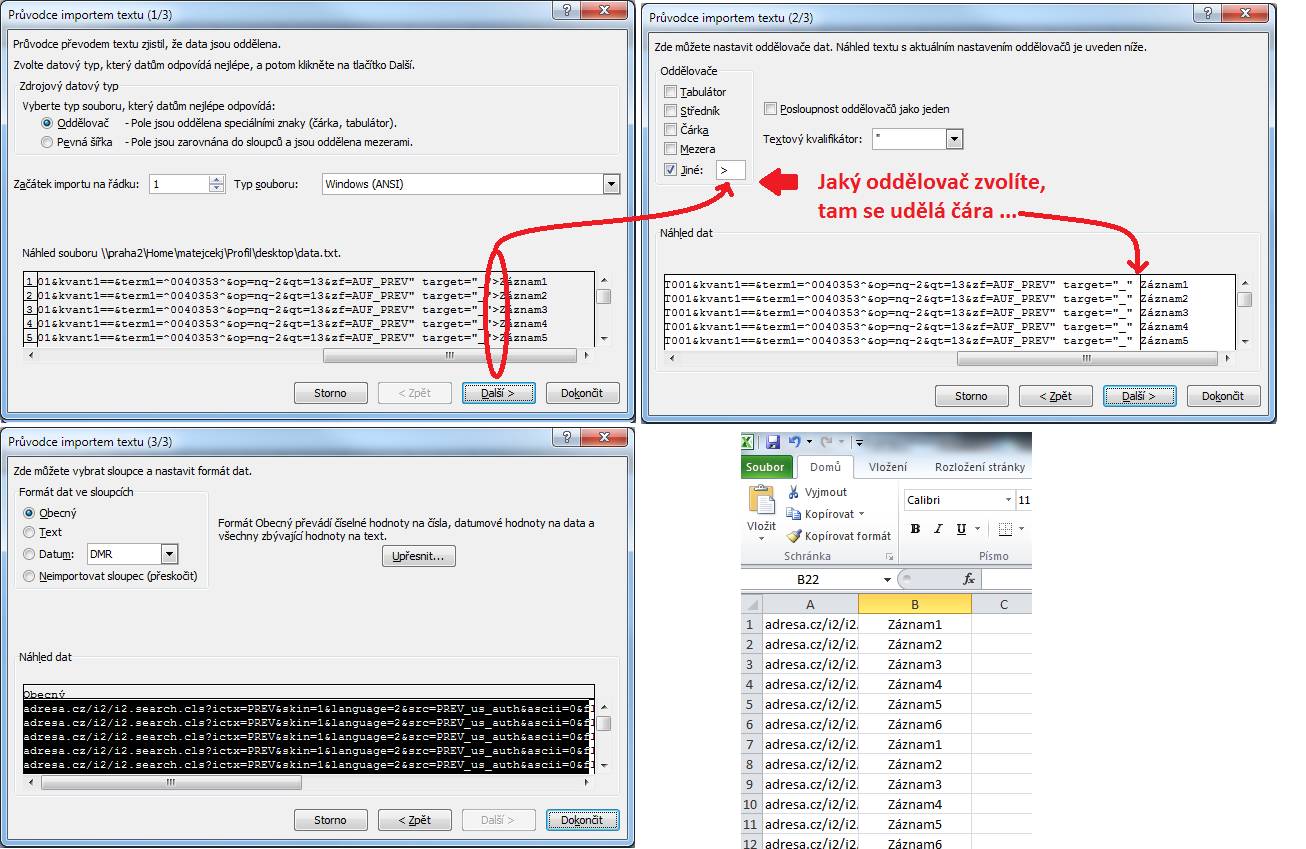
Spustit excel -> soubor otevřít -> vyhledat onen TXT a pak projít nastavením importu viz obr.
Výsledkem bude naimportovaný TXT soubor s milionama řádků kde ve sloupci A bude celý ten řetězec až ke znaku" > " ,místo kterého bude oddělovací čára a "zbytek dat" bude ve sloupci B. To samé uděláte s druhým TXT souborem a pak si ty 4 sloupce porovnáte viz můj příspěvek výše. Pokud ale nejde vůbec o ten řetězec, ale jen o ten jedinečný záznam, tak samozřejmě bych nekopíroval a neporovnával ty 4 sloupce, ale jen ty dva.
Dekuji za vase vstupy, ale vidim tam problem v tom co pisu:
jine casti radku jsou bohuzel nestejne (pred/za tim stringem jsou jinaci ![]() Radky jsou navic zprehazene tzn. ze shodny udaj je v jednom souboru na 22. radku a v druhem na radku 1584.
Radky jsou navic zprehazene tzn. ze shodny udaj je v jednom souboru na 22. radku a v druhem na radku 1584.
Protoze se domnivam, ze Excel i PSPad to umi pouze na jednom a tom stejnem radku ![]()
Jsem z to to vyseparovat string, jehoz soucasti je hodnota do jedhoho sloupce K, kde je potom uvedeno v prvnim souboru na radku 22
adresa.cz/i2/i2.search.cls?ictx=PREV&skin=1&language=2&src=PREV_us_auth&ascii=0&fld1=T001&kvant1==&term1=^0040353^&op=nq-2&qt=13&zf=AUF_PREV">Zázn
a na druhem na radku 1584:
adresa.cz/i2/i2.search.cls?ictx=PREV&skin=1&language=2&src=PREV_us_auth&ascii=0&fld1=T001&kvant1==&term1=^0040353^&op=nq-2&qt=13&zf=AUF_PREV">Záznam v DB
Neneseme odpovědnost za správnost informací a za škodu vzniklou jejich využitím. Jednotlivé odpovědi vyjadřují názory jejich autorů a nemusí se shodovat s názorem provozovatele poradny Poradte.cz.
Používáním poradny vyjadřujete souhlas s personifikovanou reklamou, která pomáhá financovat tento server, děkujeme.